kserve custom transformer 사용하기
KSERVE CUSTOM TRANSFORMER
요즈음 MLOps를 이것저것 손대면서 작업 중이다. 학습에는 Kubeflow와 MLFlow를 사용하고 모델 배포를 위해 Kserve를 사용하기로 했는데, 공식 문서가 한 20%는 부족한 것 같다. 연결된 링크가 깨져있는 경우도 종종 있고 중요한 정보가 애초에 빠져 있는 경우도 있어 결국에는 레포에 들어가 코드를 하나씩 뒤져봐야 한다.
Custom Transformer도 마찬가지다. Transformer를 작성하는 법은 적당히 나와 있으니 따라 한다 쳐도 이를 어떻게 배포하고 적용할 수 있는지에 대해서는 얘기해주지 않는다. 애초에 작성하는 법에도 모든 정보가 들어있지 않다(문서가 불완전할 뿐이지 레포에는 코드가 잘 정리되어 있으니 그래도 얘는 양호한 편이다. Serving runtime의 경우에는 한참 헤맸다). 따라서 나중에 이를 사용할 누군가를 위해 간단히 정리해본다.
Architecture
모델을 개발하다 보면 feature를 전처리해야할 일이 생기기 마련이다. 기본으로 제공되는 feature에서 새로운 feature를 만들 수도 있고 제거할 수도 있다. 이런 만들어진 모델을 배포하려면 전처리용 코드도 함께 배포해야 할 것이다.
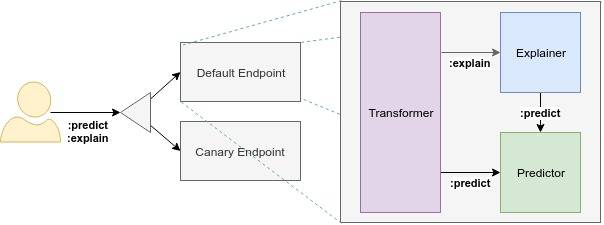
출처: 공식 페이지
kserve에서는 이런 역할을 Transformer가 담당한다. 요청이 들어오면 먼저 transformer로 전달된다. 그러면 이 transformer에서 모델이 사용할 수 있는 형태로 데이터를 전처리하는 작업을 진행하고, 그 데이터를 모델(Predictor)로 넘겨준다. Predictor에서 결과를 예측했다고 해서 그 정보가 바로 응답으로 돌아오지 않는다. 다시 한번 Transformer를 거쳐 후처리를 거친 다음에야 응답이 나온다. 그림에는 후처리에 관한 내용은 없어 헷갈릴 수 있지만 코드를 보면 알 것이다.
HOW TO
공식 문서에서부터 출발해보자. 간단한 이미지 전처리 함수를 정의한다. byte 형태로 들어오는 데이터를 읽어 이미지를 만들고 이를 normalize하는 함수다.
import base64
import io
import torchvision.transforms as transforms
from PIL import Image
def image_transform(instance):
"""converts the input image of Bytes Array into Tensor
Args:
instance (dict): The request input for image bytes.
Returns:
list: Returns converted tensor as input for predict handler with v1/v2 inference protocol.
"""
image_processing = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
byte_array = base64.b64decode(instance["data"])
image = Image.open(io.BytesIO(byte_array))
instance["data"] = image_processing(image).tolist()
return instance
그 다음으로는 이제 이 함수를 이용해 Transformer를 작성해야 한다. 문서는 gRPC와 REST가 구분되어 있는데 레포의 코드를 보면 하나의 전처리기에서 여러 프로토콜을 핸들링한다. 여기서는 REST만을 처리하는 전처리기를 만들어보자.
from kserve import Model, ModelServer, model_server
class ImageTransformer(Model):
def __init__(self, name: str, predictor_host: str):
super().__init__(name)
self.predictor_host = predictor_host
def preprocess(self, inputs: Dict) -> Dict:
return {'instances': [image_transform(instance) for instance in inputs['instances']]}
def postprocess(self, inputs: Dict) -> Dict:
return inputs
앞에서 정의한 image_transform 활용해 Transformer의 전처리를 정의한다. Transformer 또한 kserve의 모델이라는 점을 알아두자. 모델의 이름과 predictor의 주소를 받아 초기화한다. 이후에 요청이 들어오면 전처리를 진행하고 이를 predictor에 전달한다. 후처리 로직도 함께 정의하는데 이 경우에는 따로 후처리할 것 없이 모델의 결과를 그대로 반환한다. 만약 후처리가 필요하다면 inputs를 건드려주면 될 것이다.
그다음으로는 argparser가 필요하다. 기본적으로 predictor나 transformer는 pod의 spec에서 args를 받아 원하는 형태로 동작하게 설정해주는 방식이다. 모델 이름과 predictor의 주소를 커맨드라인에서 받아 처리한다.
import argparse
parser = argparse.ArgumentParser(parents=[model_server.parser])
parser.add_argument(
"--predictor_host", help="The URL for the model predict function", required=True
)
parser.add_argument(
"--model_name", help="The name that the model is served under."
)
args, _ = parser.parse_known_args()
마지막으로는 이 전처리기를 실행할 엔트리포인트가 필요하다.
if __name__ == "__main__":
model = ImageTransformer(args.model_name, predictor_host=args.predictor_host,
protocol=args.protocol)
ModelServer(workers=1).start([model])
코드는 작성 완료했다. 위의 코드는 model.py에 저장되어 있다고 하자. 이제 이를 kserve가 배포되어있는 클러스터에서 사용할 수 있게 도커 형태로 만들어주어야 한다. 먼저 필요한 패키지를 requirements.txt 형태로 만들어주자. kserve, torchvision, pillow 정도가 필요할 것이다.
kserve
torchvision
pillow==9.0.1
이제 도커 파일을 정의한다.
FROM python:3.7-slim
COPY requirements.txt .
RUN pip install -r install requirements.txt
COPY . .
RUN useradd kserve -m -u 1000 -d /home/kserve
USER 1000
ENTRYPOINT ["python", "-m", "model"]
kserve의 컨벤션인 것 같은데 non root user를 하나 생성해 그 유저가 파이썬을 실행하게 한다. 이제 빌드된 도커 이미지를 도커 레지스트리에 푸시하자. 도커 허브도 괜찮고 사적인 용도로 사용할 것이면 ECR 등 개인이 사용하는 곳에 알아서 업로드하면 된다.
docker build --tag {user}/{repo}:{tag} -f Dockerfile .
docker push {user}/{repo}:{tag}
그 다음으로는 이 전처리기를 실제로 사용하는 inference 서비스를 정의하고 배포하면 된다.
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: torch-transformer
spec:
predictor:
pytorch:
storageUri: gs://kfserving-examples/models/torchserve/image_classifier
transformer:
containers:
- image: {user}/{repo}:{tag}
name: kserve-container
command:
- "python"
- "-m"
- "model"
args:
- --model_name
- mnist
모델 이름만을 넘겨준 것을 볼 수 있는데, predictor host의 경우에는 없어도 알아서 기본 값을 채워준다. 실제 테스트를 진행하면서 predictor의 주소를 못찾아 404 Error가 나오는 경우 주소를 명시해주자. 서비스의 FQDN {predictor_svc_name}.{namespace}.svc.cluster.local을 적어도 된다.
이제 이를 배포해보고 curl 요청을 날려보면 정상적으로 동작하는 것을 확인할 수 있다.